i2 = i(同一地址)
在 Python 中,i2 = i 这种赋值方式会使 i2 和 i 指向同一个对象,因此它们的内存地址是相同的。也就是说,i2 和 i 是同一个对象的两个引用。
示例代码
1i = 422i2 = i3print(id(i), id(i2)) # 输出相同的内存地址
对于不可变对象(如整数、字符串、元组等),这种赋值方式不会引起问题,因为这些对象不能被修改。
但是,对于可变对象(如列表、字典等),这种赋值方式会导致两个变量指向同一个对象,修改其中一个变量会影响到另一个变量。
示例代码
不可变对象(整数)
xxxxxxxxxx61i = 422i2 = i3print(id(i), id(i2)) # 输出相同的内存地址4i2 = 435print(id(i), id(i2)) # 输出不同的内存地址6print(i, i2) # 输出: 42 43
可变对象(列表)
xxxxxxxxxx51i = [1, 2, 3]2i2 = i3print(id(i), id(i2)) # 输出相同的内存地址4i2.append(4)5print(i, i2) # 输出: [1, 2, 3, 4] [1, 2, 3, 4]
Tip
那么如何把i的值赋给i2而不同一地址呢?
i2 = i + 0
整除用//
int(input())
在 Python 中,input() 函数用于从标准输入(通常是键盘)读取一行输入,并返回一个字符串。无论用户输入的是什么内容,input() 函数都会将其作为字符串返回。
示例
user_input = input("请输入一些内容: ")
print(type(user_input)) # 输出: <class 'str'>
print(user_input) # 输出用户输入的内容
xxxxxxxxxx31user_input = input("请输入一些内容: ")2print(type(user_input)) # 输出: <class 'str'>3print(user_input) # 输出用户输入的内容
map()
在 Python 中,map() 函数用于将一个函数应用到一个或多个可迭代对象(如列表、元组等)的每一个元素,并返回一个迭代器。map() 函数的语法如下:
语法
xxxxxxxxxx11map(function, iterable, ...)
function:一个函数,用于应用到每个元素。iterable:一个或多个可迭代对象。
list()
在 Python 中,list() 是一个内置函数,用于将一个可迭代对象转换为列表。它可以接受任何类型的可迭代对象作为参数,并返回一个包含该可迭代对象所有元素的新列表。
语法
xxxxxxxxxx11list([iterable])
iterable:可选参数,可以是任何可迭代对象(如字符串、元组、字典、集合、迭代器等)。如果没有提供参数,则返回一个空列表。
返回值
list() 函数返回一个新的列表,包含了可迭代对象中的所有元素。
sorted()
在 Python 中,sorted() 函数用于对可迭代对象进行排序,并返回一个新的列表。sorted() 函数的语法如下:
语法
xxxxxxxxxx11sorted(iterable, key=None, reverse=False)iterable:要排序的可迭代对象。key:一个函数,用于指定排序的依据(可选)。reverse:一个布尔值,如果为True,则按降序排序(可选,默认为False)。
返回值
sorted() 函数返回一个新的列表,包含排序后的元素。
range()
在 Python 中,range() 函数返回一个不可变的序列对象,该对象生成一系列数字。range() 函数通常用于循环中,以生成一系列数字进行迭代。
语法
xxxxxxxxxx21range(stop)2range(start, stop[, step])start:可选参数,指定序列的起始值,默认值为 0。stop:必需参数,指定序列的结束值(不包含该值)。step:可选参数,指定序列的步长,默认值为 1。
返回值
range() 函数返回一个 range 对象,该对象是一个不可变的序列类型,可以用于迭代。
enumerate()
在 Python 中,enumerate() 函数用于将一个可迭代对象(如列表、元组或字符串)组合为一个索引序列,同时返回包含索引和值的元组。enumerate() 函数的语法如下:
语法
xxxxxxxxxx11enumerate(iterable, start=0)iterable:一个可迭代对象。start:可选参数,指定索引的起始值,默认值为 0。
返回值
enumerate() 函数返回一个枚举对象,该对象是一个包含索引和值的元组的迭代器。
示例
示例 1:基本用法
xxxxxxxxxx71fruits = ['apple', 'banana', 'cherry']2for index, value in enumerate(fruits):3 print(index, value)4# 输出:5# 0 apple6# 1 banana7# 2 cherry
python中的推导式
什么是推导式:
推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体。
共有三种推导,在Python2和Python3中都有支持:
列表(list)推导式
字典(dict)推导式
集合(set)推导式
列表推导式:
xxxxxxxxxx11[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]例子:
xxxxxxxxxx11my_list = [i for i in range(10) if i%2]print(my_list)Output:[1, 3, 5, 7, 9]字典推导式:
xxxxxxxxxx11{ key:value for key,value in existing_data_structure }例子:
xxxxxxxxxx11strings = ['import','is','with','if','file','exception','shim','lucy']dict = {k:v for v,k in enumerate(strings)} print(dict)例子中通过 v,k 来控制字典的key和value值。
关于enumerate()函数请参考:
https://www.runoob.com/python/python-func-enumerate.html
集合推导式:
xxxxxxxxxx11[ expression for item in Sequence if conditional ]与列表推导式用法相似
isdigit()
在 Python 中,可以使用字符串对象的 isdigit() 方法来判断一个字符是否为数字。isdigit() 方法返回一个布尔值,如果字符是数字字符,则返回 True,否则返回 False。
示例
以下是一些示例代码,展示了如何使用 isdigit() 方法判断一个字符是否为数字:
x1# 示例字符2char1 = '5'3char2 = 'a'4char3 = '3.14'5char4 = ' '6
7# 使用 isdigit() 方法判断字符是否为数字8print(char1.isdigit()) # 输出: True9print(char2.isdigit()) # 输出: False10print(char3.isdigit()) # 输出: False11print(char4.isdigit()) # 输出: False传参和函数内赋值
在你的代码中,L 传递给函数后变成 None 的原因是因为在 shulu 函数中,你重新赋值了 L,而不是修改传入的列表。Python 中的参数传递是通过引用传递的,但当你在函数内部重新赋值 L 时,它不再指向原来的列表。
xxxxxxxxxx171def shulu(L):2 L = list(map(int,input().split()))3
4def chuli(L):5 pass6
7def shuchu(L):8 pass9 10def main():11 L=[]12 shulu(L)13 chuli(L)14 shuchu(L)15
16if __name__ == '__main__':17 main()Note
引用是让一个另一个变量指向原本变量的地址吗?
是的,在 Python 中,引用意味着一个变量指向另一个变量的内存地址。对于可变类型(如列表、字典、集合等),当你将一个变量赋值给另一个变量时,两个变量实际上指向同一个内存地址。因此,对其中一个变量的修改会影响另一个变量。
不要随便赋值!!!
join()
join 函数是 Python 字符串对象的一个方法,用于将一个可迭代对象(如列表、元组等)中的元素连接成一个字符串,并在每个元素之间插入指定的分隔符。join 方法通常用于将多个字符串连接成一个字符串。
xxxxxxxxxx11separator.join(iterable)separator:用于分隔每个元素的字符串。iterable:一个可迭代对象,其元素将被连接成一个字符串。
Caution
join()方法连接的迭代器中的数据必须是字符串。如果迭代器中的元素不是字符串类型,会引发 TypeError。
示例
示例 1:连接列表中的字符串
xxxxxxxxxx51words = ['Hello', 'world', 'Python']2
3sentence = ' '.join(words)4
5print(sentence) # 输出: Hello world Python示例 2:连接元组中的字符串
xxxxxxxxxx51words = ('Hello', 'world', 'Python')2
3sentence = ', '.join(words)4
5print(sentence) # 输出: Hello, world, Python示例 3:连接字符串中的字符
xxxxxxxxxx51chars = 'abc'2
3joined_chars = '-'.join(chars)4
5print(joined_chars) # 输出: a-b-c
全局变量
在 Python 中,可以通过在函数外部定义变量来创建全局变量。要在函数内部修改全局变量,需要使用 global 关键字。以下是一个示例,展示了如何定义和使用全局变量:
xxxxxxxxxx171# 定义全局变量2global_var = 03
4def modify_global():5 global global_var # 声明使用全局变量6 global_var += 17
8def main():9 global global_var # 声明使用全局变量10 n = int(input())11 a = [[0]*(n+1)] + [[0]+list(map(int, input().split())) for i in range(n)]12 print(a)13 modify_global()14 print(f"Global variable after modification: {global_var}")15
16if __name__ == '__main__':17 main()2n皇后问题
深度优先搜索整个解空间即可
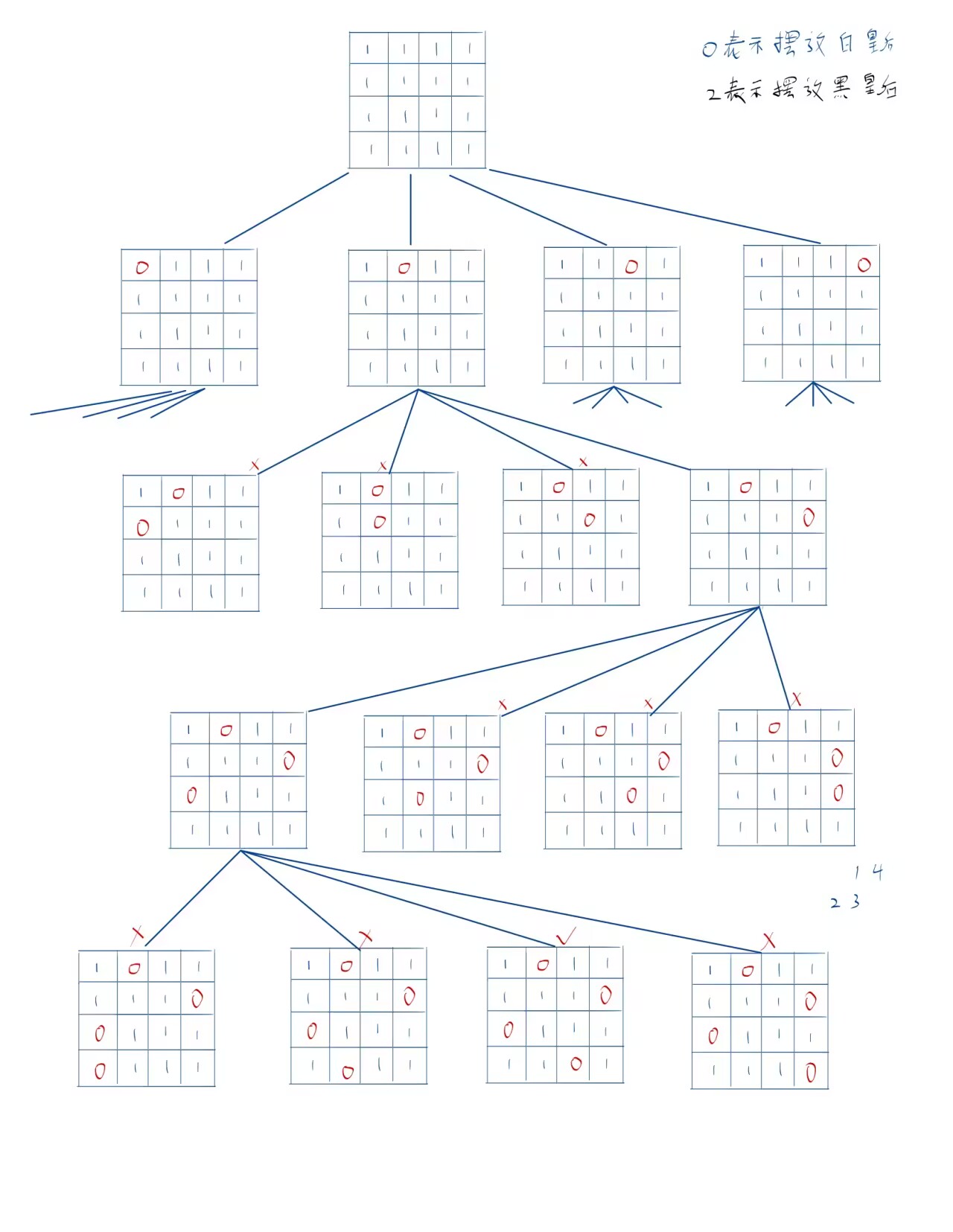
代码如下:
xxxxxxxxxx561n = int(input())2chess = [[0]*(n+1)] + [[0]+list(map(int,input().split())) for i in range(n)]3cnt = 04queen_b = [0]*(n+1)5queen_w = [0]*(n+1)6
7def check(row,j,color):8 global chess,queen_b,queen_w9 if chess[row][j] == 1:10 tmp = queen_b if color == 3 else queen_w11 for x,y in enumerate(tmp):12 if x == 0 or y == 0:13 continue14 if j == y or (x - row) == (y - j) or (x + y) == (row + j):15 return False16 return True17 return False18
19def dps_b(row):20 global n,chess,queen_b21 if row > n:22 dps_w(1)23 return 24 25 for j in range(1,n+1):26 if check(row,j,3):27 tmp = chess[row][j]28 chess[row][j] = 229 queen_b[row] = j30 dps_b(row+1)31 chess[row][j] = tmp32 queen_b[row] = 033
34
35def dps_w(row):36 global n,chess,cnt,queem_w37 if row > n:38 cnt+=139 return40
41 for j in range(1,n+1): 42 if check(row,j,2):43 tmp = chess[row][j]44 chess[row][j] = 245 queen_w[row] = j46 dps_w(row+1)47 chess[row][j] = tmp48 queen_w[row] = 049
50def main():51 global cnt52 dps_b(1)53 print(cnt)54 55if __name__ == '__main__':56 main()set()
集合不会有重复元素,可以用来清理重复元素
集合是无序的,需要转成
list然后用sort()排序二维数组排序
xxxxxxxxxx21arr = sorted(arr, key=lambda x: x[0])2arr.sorted(arr, key=lambda x: x[0])
lambda x : x[1]
lambda x: x[1] 是一个匿名函数(lambda 函数),它接受一个参数 x 并返回 x 的第二个元素(即索引为 1 的元素)。在 Python 中,lambda 函数通常用于需要一个简单函数的地方,尤其是在排序或过滤操作中。
示例解释
假设你有一个包含元组的列表,并且你想根据每个元组的第二个元素进行排序:
xxxxxxxxxx71data = [(1, 10), (2, 5), (3, 20)]2
3# 使用 lambda 函数按第二个元素排序4
5sorted_data = sorted(data, key=lambda x: x[1])6
7print(sorted_data)解释
数据:
data是一个包含元组的列表:[(1, 10), (2, 5), (3, 20)]。
排序:
sorted(data, key=lambda x: x[1\])使用sorted()函数对列表进行排序。key=lambda x: x[1]指定排序的依据是每个元组的第二个元素。
结果:
排序后的列表是:
[(2, 5), (1, 10), (3, 20)]。
isalnum()
isalnum()方法用来判断字符串中是否只包含字母或数字,并且长度要大于0,满足的话就返回True,否则返回False。